Darwin Core text guide
Darwin Core text guide
- Title
- Darwin Core text guide
- Date version issued
- 2023-09-13
- Date created
- 2009-02-12
- Part of TDWG Standard
- http://www.tdwg.org/standards/450
- This version
- http://rs.tdwg.org/dwc/terms/guides/text/2023-09-13
- Latest version
- http://rs.tdwg.org/dwc/terms/guides/text/
- Previous version
- http://rs.tdwg.org/dwc/terms/guides/text/2021-07-15
- Abstract
- Guidelines for implementing Darwin Core in Text files.
- Contributors
- Tim Robertson (Global Biodiversity Information Facility), Markus Döring (Global Biodiversity Information Facility), John Wieczorek (VertNet), Renato De Giovanni (Centro de Referência em Informação Ambiental), Dave Vieglais (KU Natural History Museum), Steve Baskauf (Vanderbilt University Libraries), Gail Kampmeier (Illinois Natural History Survey)
- Creator
- Darwin Core Maintenance Group
- Bibliographic citation
- Darwin Core Maintenance Group. 2023. Darwin Core text guide. Biodiversity Information Standards (TDWG). http://rs.tdwg.org/dwc/terms/guides/text/2023-09-13
1 Introduction
This document provides guidelines for formatting and sharing Darwin Core terms in fielded text formats, such as one or more comma separated value (CSV) files. Data conforming to the Simple Darwin Core (CSV format and having the first row include Darwin Core standard term names) MAY be shared in a single file, while a non-standard text file MAY be understood using an XML metafile to describe its contents and formatting. A Darwin Core Archive is an example of an implementation of the Darwin Core Text recommendation.
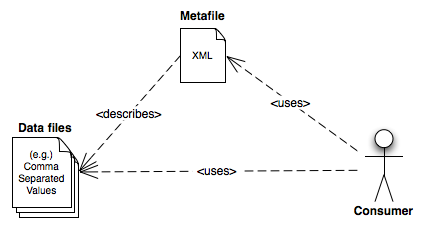
More complex structure MAY be shared in multiple related files. The description of content and relationships between files can be achieved using the metafile (meta.xml). This guideline makes recommendations for the simple case of a core file, upon which Darwin Core records are based, and extensions, which are linked to records in that core file. Specifically, extension records have a many-to-one relationship with records in the core file. For example, a core file might contain specimen records, with one specimen per row in the file, while an extension file contains one or more identifications for those specimens, with one identification per row in the extension file, and with an identifier to the specimen for each identification row. This example would allow many identifications to be associated with each specimen.
1.1 Status of the content of this document
All sections of this document are normative, except for examples, whose sections are marked as non-normative.
1.1.1 RFC 2119 key words
The key words “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document are to be interpreted as described in BCP 14 [RFC2119] [RFC8174] when, and only when, they are written in capitals (as shown here).
1.2 Simple example metafile content (non-normative)
A simple comma separated values (CSV) data file named specimens.csv with the following content:
ID,Species,Count
123,"Cryptantha gypsophila Reveal & C.R. Broome",12
124,"Buxbaumia piperi",2
can be described with the following Darwin Core metafile (meta.xml):
<?xml version="1.0" encoding="UTF-8"?>
<archive xmlns="http://rs.tdwg.org/dwc/text/"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xsi:schemaLocation="http://rs.tdwg.org/dwc/text/ http://rs.tdwg.org/dwc/text/tdwg_dwc_text.xsd">
<core rowType="http://rs.tdwg.org/dwc/xsd/simpledarwincore/SimpleDarwinRecord" ignoreHeaderLines="1">
<files>
<location>http://data.gbif.org/download/specimens.csv</location>
</files>
<field index="0" term="http://rs.tdwg.org/dwc/terms/occurrenceID" />
<field index="1" term="http://rs.tdwg.org/dwc/terms/scientificName" />
<field index="2" term="http://rs.tdwg.org/dwc/terms/individualCount" />
<!-- A constant value has no index, but applies to all rows -->
<field term="http://rs.tdwg.org/dwc/terms/datasetID" default="urn:lsid:tim.lsid.tdwg.org:collections:1"/>
</core>
</archive>
These same data could be understood without the metafile if the first row of the CSV file contained Darwin Core term names, such as:
type,institutionCode,collectionCode,catalogNumber,scientificName,individualCount,datasetID
PhysicalObject,ANSP,PH,123,"Cryptantha gypsophila Reveal & C.R. Broome",12,urn:lsid:tim.lsid.tdwg.org:collections:1
PhysicalObject,ANSP,PH,124,"Buxbaumia piperi",2,urn:lsid:tim.lsid.tdwg.org:collections:1
2 Metafile content
The text metafile schema provides technical details for the structure of a metafile by defining the elements and attributes necessary to describe the contents and relationships between text files. These elements and attributes, with descriptions and specifications for their use in a metafile, are described in the following table. The metafile MUST be named meta.xml.
2.1 The <archive> element
The <archive> element is the container for the list of related files (one core and zero or more extensions). The <archive> element SHOULD have a metadata attribute.
2.1.1 Attributes
| Attribute | Description | Required | Default |
|---|---|---|---|
metadata |
If used, the value MUST be a qualified Uniform Resource Locator (URL) defining the location of a metadata description of the entire archive. The format of the metadata is not prescribed, but a standardized format such as Ecological Metadata Language (EML), Federal Geographic Data Committee (FGDC), or a format from the ISO 19115 family is RECOMMENDED. | no |
2.1.2 Elements
| Element | Description |
|---|---|
<core> |
An <archive> MUST contain exactly one <core> element, representing the data entity (the actual file and its column header mappings to Darwin Core terms) upon which records are based. If extensions are being used, each record in the core data MUST have a unique identifier. The field for this identifier MUST be specified in an explicit <id> field in order to associate extension records with the core record. |
<extension> |
An <archive> MAY define zero or more <extension> elements, each representing an individual extension entity directly related to the core. In addition to the general file attributes described below, every extension entity MUST have an explicit <coreid> field to relate the extension record to a row in the core entity. The extension itself does not have to have a unique ID field and many rows can point to the same core record. |
2.2 The <core> or <extension> element
2.2.1 Attributes
| Attribute | Description | Required | Default |
|---|---|---|---|
rowType |
The row type is REQUIRED and MUST be a Unified Resource Identifier (URI) for the term identifying the class of data represented by each row. Classes MAY be defined outside the Darwin Core specification if denoted by a URI. For convenience the URIs for classes defined by the Darwin Core are: dwc:Occurrence: http://rs.tdwg.org/dwc/terms/Occurrence, dwc:Organism: http://rs.tdwg.org/dwc/terms/Organism, dwc:MaterialEntity: http://rs.tdwg.org/dwc/terms/MaterialEntity, dwc:MaterialSample: http://rs.tdwg.org/dwc/terms/MaterialSample, dwc:Event: http://rs.tdwg.org/dwc/terms/Event, dcterms:Location: http://purl.org/dc/terms/Location, dwc:GeologicalContext: http://purl.org/dc/terms/GeologicalContext, dwc:Identification: http://rs.tdwg.org/dwc/terms/Identification, dwc:Taxon: http://rs.tdwg.org/dwc/terms/Taxon, dwc:ResourceRelationship: http://rs.tdwg.org/dwc/terms/ResourceRelationship, dwc:MeasurementOrFact: http://rs.tdwg.org/dwc/terms/MeasurementOrFact, chrono:ChronometricAge: http://rs.tdwg.org/chrono/terms/ChronometricAge, |
yes | |
fieldsTerminatedBy |
Specifies the delimiter between fields. Typical values MAY be , or \t for CSV or Tab files respectively. |
no | , |
linesTerminatedBy |
Specifies the row separator character. | no | \n |
fieldsEnclosedBy |
Specifies the character used to enclose (mark the start and end of) each field. CSV files frequently use the double quote character ("), which is the default value if none is explicitly provided. Note that a comma separated value file that has commas within the content of any field MUST have an enclosing character. |
no | " |
encoding |
Specifies the character encoding for the data file. The encoding is extremely important, but often ignored. The most frequently used encodings are: UTF-8: 8-bit Unicode Transformation Format, UTF-16: 16-bit Unicode Transformation Format, ISO-8859-1: commonly known as “Latin-1” and a common default on systems configured for a single western European language, Windows-1252: commonly known as “WinLatin” and a common default of legacy versions of Microsoft Windows-based operating systems. |
no | UTF-8 |
ignoreHeaderLines |
Specifies the number lines to ignore from the beginning of the file. This MAY be used to ignore files with column headings or preamble comments. | no | 0 |
dateFormat |
If date fields throughout the entire dataset follow a consistent format, this format MAY be specified by the dateFormat parameter. This SHOULD be considered a ‘hint’ for consumers in cases where the date fields do not follow the RECOMMENDED ISO 8601:2019-1 specification. The format for this parameter MUST be a combination of year (YYYY), month (MM), and day (DD) indicators in combination with a separator (/ or -). Examples: DDMMYYYY for dates of the form 21121978, DD-MM-YYYY for dates of the form 21-12-1978, MMDDYYYY for dates of the form 12211978, MM-DD-YYYY for dates of the form 12-21-1978, YYYYMMDD for dates of the form 19781221. |
no | YYYY-MM-DD |
2.2.2 Elements
| Element | Description |
|---|---|
<files> |
A <core> element MUST contain one <files> element to locate the data being described. An <extension> element, if present, MUST also contain one <files> element. |
<id> |
If extensions are being used, the <core> MUST contain an <id> element, which indicates the identifier for a record. |
<coreid> |
If an extension is used, the <extension> element MUST contain a <coreid> element, which indicates the column in the extension file that contains the core record identifier (the value that is supposed to match the <id> in the core file). |
<field> |
A <core> or <extension> element MUST contain one or more <field> elements, each representing a ‘column’ in the row. |
2.3 <files> element
The <files> element MUST contain one or more <location> elements, each defining where a file resides. Each <core> or <extension> entity MAY be composed from one or more files. If an entity has data in more than one file, the <location> element MUST be present once for each distinct <file> that makes up the entity.
2.3.1 Elements
| Element | Description |
|---|---|
<location> |
Specifies the location of the <file> being described. The <location> element MUST take one of the following forms: 1) a web accessible URL such as http://www.gbif.org/data/specimen.csv or ftp://ftp.gbif.org/tim/specimen.txt, or 2) a file path relative to the location of the metafile such as specimen.txt, ./specimen.txt, ./data/specimen.txt. |
2.4 The <field> element
The <field> element is used to specify the location and content of data within a <file>. There MUST be one <field> element for every term being shared for the entity, whether explicitly or through the use of a <default> value for all rows in the <file>.
2.4.1 Attributes
| Attribute | Description | Required | Default |
|---|---|---|---|
index |
Specifies the position of the column in the row. The first column has an index of 0, the second column has an index of 1, etc. If no column index is specified, the term and a default constant value for it MAY be defined for all rows. | no | |
term |
MUST be a Unified Resource Identifier (URI) for the term represented by this <field>. For example, a column containing the scientific name would have term="http://rs.tdwg.org/dwc/terms/scientificName". Terms outside of the Darwin Core specification, such as those from the Dublin Core Metadata Initative, MAY be used. For example, dcterms:modified would be term="http://purl.org/dc/terms/modified". |
yes | |
default |
Specifies a value to use if one is not supplied for the <field> in a given row. If no index is supplied for a given <field>, the <default> MAY be used to define a constant for all rows for that <field>. |
no | |
vocabulary |
When present, MUST be a Unified Resource Identifier (URI) for a vocabulary that the source values for this <field> are based on. The URI SHOULD resolve to some machine readable definition such as SKOS or RDF, or a simple text or HTML file such as often found for ISO or RFC standards. For example http://rs.gbif.org/vocabulary/gbif/nomenclatural_code.xml, http://www.ietf.org/rfc/rfc3066.txt or http://www.iso.org/iso/list-en1-semic-3.txt. |
no |
3 Implementation guide (non-normative)
A Darwin Core Archive is an example of an implementation of the Darwin Core Text recommendation.
3.1 Extension example (non-normative)
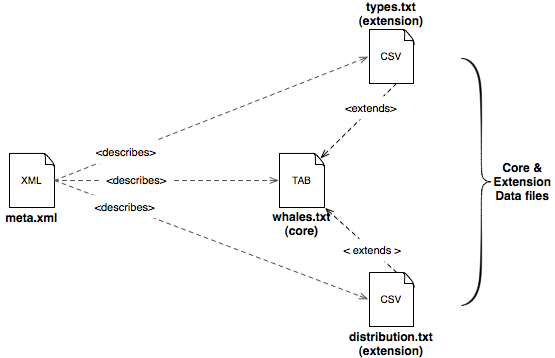
The following example illustrates the use of extensions. In this example there are three files in the archive, all of which are located in the same directory as the metafile. The whales.txt file acts as a core file of Taxon records. The whales.txt file is extended by two other files, types.txt and distribution.txt. The types.txt file contains records specified in an external definition at http://rs.gbif.org/terms/1.0/TypesAndSpecimen and consists of Dublin Core and Darwin Core terms, while the distribution.txt file contains records specified in the Species Distribution Extension at http://rs.gbif.org/terms/1.0/Distribution and consists of Darwin Core terms plus an additional term for threatStatus. Both extension files are related to the core file by the dwc:taxonID fields. This archive contains information about whale species, type specimen records for those species, and lists of countries and the threat status for those species in those countries.
<?xml version="1.0" encoding="UTF-8"?>
<archive xmlns="http://rs.tdwg.org/dwc/text/"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xsi:schemaLocation="http://rs.tdwg.org/dwc/text/ http://rs.tdwg.org/dwc/text/tdwg_dwc_text.xsd">
<core encoding="UTF-8" fieldsTerminatedBy="\t" linesTerminatedBy="\n" ignoreHeaderLines="1" rowType="http://rs.tdwg.org/dwc/terms/Taxon">
<files>
<location>whales.txt</location>
</files>
<id index="0" />
<field index="0" term="http://rs.tdwg.org/dwc/terms/taxonID" />
<field index="1" term="http://purl.org/dc/terms/modified" />
<field index="2" term="http://rs.tdwg.org/dwc/terms/scientificName"/>
<field index="3" term="http://rs.tdwg.org/dwc/terms/acceptedNameUsageID"/>
<field index="4" term="http://rs.tdwg.org/dwc/terms/parentNameUsageID"/>
<field index="5" term="http://rs.tdwg.org/dwc/terms/originalNameUsageID"/>
</core>
<extension encoding="UTF-8" fieldsTerminatedBy="," linesTerminatedBy="\n" fieldsEnclosedBy='"' ignoreHeaderLines="1" rowType="http://rs.gbif.org/terms/1.0/TypesAndSpecimen">
<files>
<location>types.csv</location>
</files>
<coreid index="0" />
<field index="1" term="http://purl.org/dc/terms/bibliographicCitation"/>
<field index="2" term="http://rs.tdwg.org/dwc/terms/catalogNumber"/>
<field index="3" term="http://rs.tdwg.org/dwc/terms/collectionCode"/>
<field index="4" term="http://rs.tdwg.org/dwc/terms/institutionCode"/>
<field index="5" term="http://rs.tdwg.org/dwc/terms/typeStatus"/>
</extension>
<extension encoding="UTF-8" fieldsTerminatedBy="," linesTerminatedBy="\n" fieldsEnclosedBy='"' ignoreHeaderLines="1" rowType="http://rs.gbif.org/terms/1.0/Distribution">
<files>
<location>distribution.csv</location>
</files>
<coreid index="0" />
<field index="1" term="http://rs.tdwg.org/dwc/terms/countryCode"/>
<field index="2" term="http://rs.gbif.org/terms/1.0/threatStatus"/>
<field index="3" term="http://rs.tdwg.org/dwc/terms/occurrenceStatus"/>
</extension>
</archive>
4 Database example (non-normative)
4.1 MySQL
It is very easy to produce fielded text using the SELECT INTO … outfile command from MySQL. The encoding of the resulting file will depend on the server variables and collations used, and might need to be modified before the operation is done. Note that MySQL will export NULL values as \N by default. Use the IFNULL() function as shown in the following example to avoid this.
SELECT
IFNULL(id, ''), IFNULL(scientific_name, ''), IFNULL(count,'')
INTO outfile '/tmp/dwc.txt'
FIELDS TERMINATED BY ','
OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\n'
FROM
dwc;